728x90
1. 데이터
: 추론과 추정의 근거를 이루는 사실
1) 특성
- 존재적 특성: 객관적 사실(fact, raw material)
- 당위적 특성: 추론, 예측, 전망, 추정을 위한 근거(basis)
2) 유형
| 구분 | 형태 | 특징 | 예 |
| 정성적 데이터 (Qualitative data) |
언어, 문자 등 | 저장, 검색, 분석에 많은 비용이 소모 됨 | 회사 매출이 증가함 |
| 정량적 데이터 (Quantitative data) |
수치, 도형, 기호 등 | 정형화가 된 데이터이기 때문에 비용 소모가 적음 | 나이, 몸무게, 주가 등 |
| 구분 | 의미 | 특징 | 상호작용 | 예 |
| 암묵지 | 학습과 경험을 통해 개인에게 체화되어 있지만 겉으로는 드러나지 않는 지식 | 중요하지만 다른 사람에게 공유되기 어려움 | 공통화, 내면화 | 자전거 타기, 피아노연주 |
| 형식지 | 문서나 매뉴얼처럼 형상화된 지식 | 전달과 공유가 용이 | 표출화, 연결화 | 교과서, 비디오, DB |
3) DIKW
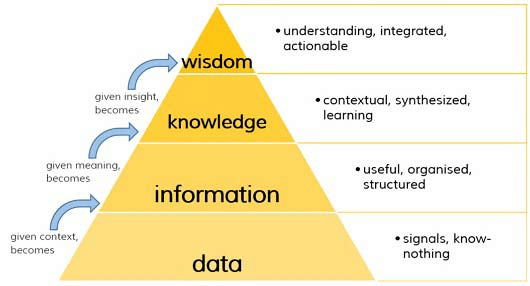
- 데이터(Data): 개별 데이터 자체로는 의미가 중요하지 않은 객관적 사실로 순수한 수치가 기호를 의미
ex) A마트는 100원에 B마트에는 200원에 연필을 판매한다. - 정보(Information): 데이터의 가공, 처리와 데이터간 연관관계 속에서 의미가 도출된 것
ex) A마트의 연필이 더 싸다. - 지식(Knowledge): 상호 연결된 정보 패턴을 이해하여 이를 토대로 예측한 결과물
ex) 상대적으로 저렴한 A마트에서 연필을 사야한다. - 지혜(Wishdom): 근본 원리에 대한 깊은 이해를 바탕으로 도출되는 창의적 아이디어
ex) A마트의 다른 상품들도 B마트보다 쌀 것이라고 판단한다.
4) 데이터 양의 단위
| 단위 | 데이터량 |
| 바이트(B) | 1byte |
| 킬로바이트(KB) | 1024B |
| 메가바이트(MB) | 1024KB |
| 기가바이트(GB) | 1024MB |
| 테라바이트(TB) | 1024GB |
| 페타바이트(PB) | 1024TB |
| 엑사바이트(EB) | 1024PB |
| 제타바이트(ZB) | 1024EB |
| 요타바이트(YB) | 1024ZB |
5) 데이터유형
| 구분 | 정형데이터 | 반정형데이터 | 비정형데이터 |
| 형태 | 고정된 필드 | 스키마, 메타데이터 | 없음 |
| 연산 | 가능 | 불가능 | 불가능 |
| 저장형태 | 주로 관계형 데이터베이스 (RDBMS)에 저장됨 |
주로 파일로 저장됨 | 주로 NoSQL로 저장됨 |
| 수집 난이도 | 쉬움 | 중간 | 높음 |
| 처리난이도 | 쉬움 형식이 정해져 있기 때문 |
중간 보통 API형태로 제공되기 때문에 데이터 처리기술(파싱)이 요구됨 |
어려움 텍스트 마이닝 혹은 파일일 경우 파일을 데이터 형태로 파싱해야하기 때문 |
| 예시 | 관계형 데이터베이스, 스프레드시트, CSV |
XML, HTML, JSON, 로그형태(웹로그, 센서데이터) |
소셜데이터(트위터, 페이스북), 영상, 이미지, 음성, 텍스트(word, PDF) |
2. 데이터 관련 기술
1) 개인정보 비식별 기술
| 비식별 기술 | 내용 | 예시 |
| 데이터 마스킹 | 데이터이 길이, 유형, 형식과 같은 속성을 유지한 채, 새롭고 읽기 쉬운 데이터를 익명으로 생성하는 기술 |
김철수, 35세, 서울거주, 한국대 졸업 → 김**, 35세, 서울거주, **대학 졸업 |
| 가명처리 | 개인정부 주체의 이름을 다른 이름으로 변경하는 기술 | 김철수, 35세, 서울거주, 한국대 졸업 → 아무개, 30대, 서울거주, 국내대 졸업 |
| 총계처리 | 데이터의 총합값을 보임으로써 개별 데이터의 값을 보이지 않도록 함 | 아무개 180cm, 김철수 170cm, 이영희 160cm, 박희영 150cm → 수학과 학생 키 합: 660cm, 평균키: 165cm |
| 데이터 값 삭제 | 데이터 공유, 개발 목적에 따라 데이터 셋에 구성된 값 중에 필요 없는 값 또는 개인식별에 중요한 값 삭제 | 김철수, 35세, 서울거주, 한국대 졸업 → 35세, 서울 거주 주민등록번호 950123-1234567 → 90년대생, 남자 |
| 데이터 범주화 | 데이터 값을 범주의 값으로 변환하여 값을 숨김 | 김철수, 35세 → 김씨, 30~39세 |
2) 데이터 무결성(Data integrity)
- 데이터 변겅/수정 시 여러가지 제한을 두어 데이터 정확성을 보증하는 것
- 데이터베이스 내의 데이터에 대한 정확한 일관성, 유효성, 신뢰성을 보장하기 위함
- 무결성 유형: 개체무결성(Entity integrity), 참조 무결성(Referential integrity), 범위 무결성(Domain integrity) 등
3) 데이터 레이크(Data Lake)
- 다량의 정보 속에서 의미있는 내용을 찾기 위해 방식에 상관없이 데이터를 저장하는 시스템
- 대용량의 정형 및 비정형 데이터를 저장할 뿐 아니라 접근도 쉽게할 수 있는 대규모 저장솔르 의미
3. 데이터베이스(Database)
: 문자, 기호, 영상 등 상호 관련된 다수의 콘텐츠를 정보 처리 및 정보통신 기기에 의하여 체계적으로 수집 및 축적하여 다양한 용도와 방법으로 이용할 수 있도록 정리한 정보의 집합체
1) 특징
- 통합된 데이터(Integrated data): 동일한 내용의 데이터가 중복되어 있지 않음.
- 저장된 데이터(Stored data): 컴퓨터가 접근할 수 있는 저장 매체에 저장되는 것.
- 공용 데이터(Shared data): 여러 사용자가 서로 다른 목적으로 데이터를 공동으로 이용하는 것.
- 변화되는 데이터(Changable data): 새로운 데이터의 삽입, 기존 데이터의 삭제, 갱신으로 항상 데이터는 변화함.
2) 1980년대 데이터베이스: OLTP와 OLAP
- OLTP(On-Line Transaction Processing): 호스트 컴퓨터가 데이터베이스를 액세스하고, 바로 처리 결과를 돌려보내는 형태
- OLAP(On-Line Analytical Processing): 다양한 비즈니스 관점에서 쉽고 빠르게 다차원적인 데이터에 접근하여 의사결정에 활용할 수 있는 정보를 얻을 수 있게 해주는 기술
| 구분 | OLTP (데이터 갱신) | OLAP (데이터 조회) |
| 데이터 구조 | 복잡 | 단순 |
| 데이터 갱신 | 동적으로 순간적 | 정적으로 주기적 |
| 응답시간 | 수 초 이내 | 수 초에서 몇 분 사이 |
| 데이터 범위 | 수 십일 전후 | 오랜 기간 저장 |
| 데이터 성격 | 정규적인 핵심 데이터 | 비정규적인 읽기 전용 데이터 |
| 데이터 크기 | 수 기가 바이트 | 수 테라 바이트 |
| 데이터 내용 | 현재 데이터 | 요약된 데이터 |
| 데이터 특성 | 트랜잭션 중심 | 주제중심 |
| 데이터 엑세스 빈도 | 높음 | 보통 |
| 질의 결과 예측 | 주기적이며 예측가능 | 예측 어려움 |
3) 2000년대 데이터베이스: CRM과 SCM
- CRM(Customer Relationship Management, 고객관계관리): 기업이 고객과 관련된 내외부 자료를 분석, 통합해 고객 중신 자원을 극대화하고 이를 토대로 고객특성에 맞게 마케팅 활동을 계획,지원,평가하는 과정
- SCM(Supply Chain Management, 공급망관리): 기업에서 원재료의 생산,유통 등 모든 공급망 단계를 최적화해 수요자가 원하는 제품을 원하는 시간과 장소에 제공하는 것
4) 분야별 데이터베이스
i. 제조분야
- ERP(Enterprise Resource Planning): 인사, 재무, 생산 등 경영자원을 하나의 통합 시스템으로 재구축함으로써 생산성을 극대화하는 방법
- BI(Business Intelligence): 기업이 보유하고 있는 데이터를 정리하고 분석해 의사결정에 활용하는 일련의 프로세스
- CRM(Customer Relationship Management): 고객중심자원 극대화
- RTE(Real-Time Enterprise): 회사의 전 부분을 하나로 통합관리하는 실시간 기업의 새로운 기업경영시스템
ii. 금융부문
- EAI(Enterprise Application Integration): 필요한 정보를 중앙 집중적으로 통합, 관리, 사용할 수 있는 환경을 구현하는 것
- EDW(Enterprise Data Warehouse): 기존 Data Warehouse를 전사적으로 확장한 모델로 BRP, CRM, BSC같은 다양한 분석 애플리케이션들을 위한 원천
* BRP(Business Process Re-engineering): 업무재설계
* BSC(Balanced Scorecard): 균형성과표
iii. 유통부문
- KMS(Knowledge Management System): 지식관리시스템
- RFID(RF, Radio Frequency): 주파수를 이용해 ID를 식별하는 시스템, 전자태그
5) 사회기반 구조로서의 데이터베이스
- EDI(Electronic Data Interchange): 주문서, 납품서, 청구서 등 무역에 필요한 각종 서류를 표준화된 양식을 통해 전자적 신호로 바꿔 거래처에 전송하는 시스템
- VAN(Value Added Network): 부가가치통신망, 공중 전기통신사업자로부터 통신회선을 차용하여 독자적인 네트워크를 형성하는 것
- CALS(Commerce At Light Speed): 제품의 라이프 사이클 전반에 관련된 데이터를 통합하고 공유, 교환할 수 있도록 한 경영통합 정보 시스템
- 제품의 라이프 사이클: 제품의 설계, 개발, 생산에서 유통, 폐기 까지의 과정
- 전자상거래 구축을 위해 기업 내에서 비용 절감과 생산성 향상을 추구할 목적으로 시작
- 1980년 초, 미 국방성에서 효율적인 군수 조달을 위한 목적으로 개발됨
i. 물류부문
- CVO(Commercial Vehicle Operation System): 화물운송정보
- PORT-MS(황만운영정보시스템)
- KROIS(철도운영정보시스템)
ii. 지리/교통부문
- GIS(Geographic Information System): 지리정보시스템
- RS(Remode Sensing): 원격탐사
- GPS(Global Positioning System): 범지구위치결정시스템
- ITS(Intelligent Transport System): 지능형교통시스템
- LBS(Location Based Service): 위치기반서비스
- SIM(Spatial Information Management): 공간정보관리
iii. 의료부문
- PACS(Picture Archiving and Commmunications System)
- U헬스(Ubiquitous-Health)
iv. 교육부문
- NEUS(National Education Information System): 교육행정정보시스템
4. 참고
1) B2B
- 기업과 기업사이의 거래를 기반으로 한 비즈니스 모델
ex) 기업이 필요로 하는 장비, 재료나 공사입찰 등
2) B2C
- 기업과 고객사이의 거래를 기반으로 한 비즈니스 모델
ex) 이동통신사, 여행회사, 신용카드회사, 지마켓 등
3) 블록체인(Block Chain)
- 거래정보를 하나의 덩어리로 보고 이를 차례로 연결한 거래장부
- 거래에 참여하는 모든 사용자에게 거래내역을 보내주며 거래 때마다 이를 대조해 데이터 위조를 막는 방식
728x90
'통계학 > ADP' 카테고리의 다른 글
| [ADP] DBMS와 SQL (1) | 2025.01.15 |
|---|---|
| [ADP] 빅데이터의 이해 (0) | 2025.01.14 |
| [ADP] 기초통계분석 (2) | 2024.12.06 |
| [ADP] 통계분석의 이해 (1) | 2024.12.01 |
| [빅데이터분석기사] Ch1. 빅데이터 분석 기획 (1) (1) | 2022.06.07 |