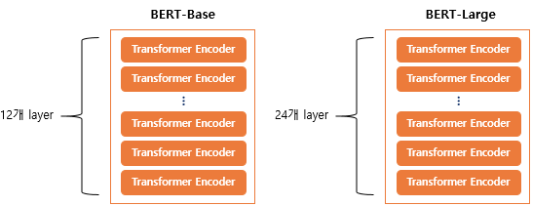
1. Word2Vec - CBOWCBOW에 대한 정의는 아래 게시글 참조 [NLP] Word Embedding자연어처리 공부중입니다. 잘못된 부분은 편히 댓글 부탁드립니다.1. 워드 임베딩이란?단어를 인공신경망 학습을 통해 벡터화하는 하는 것즉 텍스트를 숫자로 변환하는 방법2. 희소 표현(Sparse Rehello-heehee.tistory.com2. CODE1) Gensim Gensim: topic modelling for humansEfficient topic modelling in Pythonradimrehurek.com가장 많이 사용되고 상용화되어있는 Gensim의 Word2Vec이다.from gensim.models import Word2Vecfrom gensim.models.word2vec i..