728x90
1. BERT란 무엇인가
17. BERT(Bidirectional Encoder Representations from Transformers)
트랜스포머(transformer)의 등장 이후, 다양한 자연어 처리 태스크에서 사용되었던 RNN 계열의 신경망인 LSTM, GRU는 트랜스포머로 대체되어가는 추세입니다. 이에 따…
wikidocs.net
- Bidirectional Encoder Representations from Transformers
- Tranformer 계열의 자연어 처리 모델
- 다음에 올 단어를 예측하는데 자주 사용하는 언어모델
2. BERT의 구조
- BERT의 기본구조는 Transformer의 Encoder를 쌓아올린 구조로 Base버전에는 총 12개, Large버전에는 24개를 쌓음
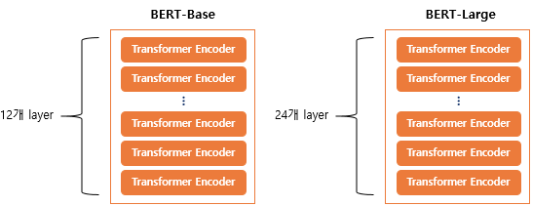
- Input: 단어를 토큰(Token)으로 변환한 뒤 임베딩(Embedding)하여 입력
- Output: 문맥을 반영하여 각 단어 또는 문장의 벡터(Embedding)
- 각 layer에 Self-Attention
[NLP] Word Embedding
자연어처리 공부중입니다. 잘못된 부분은 편히 댓글 부탁드립니다.1. 워드 임베딩이란?단어를 인공신경망 학습을 통해 벡터화하는 하는 것즉 텍스트를 숫자로 변환하는 방법2. 희소 표현(Sparse Re
hello-heehee.tistory.com
3. BERT의 특징과 토크나이저
- 위키피디아(25억개 단어)와 BooksCorpus(8억개의 단어)와 같은 Label이 없는 텍스트 데이터로 사전 훈련된 언어모델
- 양방향성(Bidirectional)
- 문장의 양쪽 방향에서 동시에 학습 - Self-Attention
[NLP] Encoder-Decoder와 Attention
1. Encoder 와 DecoderEncoder: Input data를 받아 압축 데이터(context vector)로 변환 및 출력Decoder: Encoder와 반대로 압축 데이터(context vector)를 입력 받아 Output data를 출력데이터를 압축하여 전달하는 이유는
hello-heehee.tistory.com
- 단어보다 더 작은 단위로 쪼개는 서브워드 토크나이저 사용
- 자주 등장하는 단어는 단어 집합에 추가하지만, 자주 등장하지 않는 단어는 더 작은 단위인 서브워드로 분리되어 단어집합에 추가
ex) "embeddings" 라는 단어는 "em", "##bed", "##ding", "#s"로 분리 됨
# Bert-base의 토크나이저
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
result = tokenizer.tokenize('Here is the sentence I want embeddings for.')
print(result)
"""
['here', 'is', 'the', 'sentence', 'i', 'want', 'em', '##bed', '##ding', '##s', 'for', '.']
"""
print(tokenizer.vocab['here']) #"here"이란 단어가 있는지 조회
"""
2182 #2182란 정수로 인코딩 됨
"""
# BERT의 단어 집합을 vocabulary.txt에 저장
with open('vocabulary.txt', 'w') as f:
for token in tokenizer.vocab.keys():
f.write(token + '\n')
#DataFrame 형태로 저장
import pandas as pd
df = pd.read_fwf('vocabulary.txt', header=None)4. BERT의 Pre-Training
1) MLM(Masked Language Model)
- 입력 테스트데이터 중 15%의 단어를 랜덤으로 마스킹(Masking)하는 방법
- 이 15%의 단어들 중 일부는 [MASK]로 가리고, 일부는 단어가 변경됨 - 인공신경망에게 이 가려진 단어들을 예측하도록 함
2) NSP(Next Sentence Prediction)
- 두 개의 문장이 이어지는 문장인지 아닌지 맞추는 방식으로 훈련

5. BERT 파생 모델
- ALBERT: A Lite BERT
- BERT의 경량화 버전으로 파라미터 수를 줄여 학습 속도와 효율성을 높인 모델 - RoBERTa: A Robustly Optimized BERT Pretraining Approach
- 기존 BERT보다 학습데이터를 많이 사용하고 최적화하여 성능을 향상시킨 모델 - ELECTRA: Efficiently Learning an Encoder that Classifies Token Replacements Accurately
- DistilBERT:
- BERT모델의 경량화 버전으로 속도와 효율성 중시
- 기존 BERT보다 성능과 정밀도가 떨어질 수 있음
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
from torch import nn
import torch
# 모델과 토크나이저 로드
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertForSequenceClassification.from_pretrained('distilbert-base-uncased')
# 입력 텍스트
text = "DistilBERT is a smaller version of BERT."
# 텍스트 토큰화
inputs = tokenizer(text, return_tensors="pt")
# 모델 추론
outputs = model(**inputs)
# 결과 출력
logits = outputs.logits
print("Logits:", logits)- TimeBert
- 시간정보를 추가한 Bert모델 - BERTology
- DeBERTa: Decoding-enhanced BERT with disentangled attention
- Disentangled Attention 기법과 향상된 디코딩 전략을 사용하여 BERT보다 성능이 뛰어남
c.f) BERT Embedding과 LSTM 모델로 이상치 탐색
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
from transformers import BertTokenizer, BertModel
# 1. 데이터 준비
data = {
'timestamp': ['2023-12-01 10:00', '2023-12-01 11:00', '2023-12-01 12:00', '2023-12-02 10:00'],
'text': [
"Amazing product! Fantastic quality.",
"Terrible service, very disappointing.",
"Amazing product! Excellent service.",
"Great product, amazing value!"
]
}
df = pd.DataFrame(data)
df['timestamp'] = pd.to_datetime(df['timestamp'])
# 2. 텍스트 임베딩 (BERT 사용)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
def bert_embedding(text):
tokens = tokenizer(text, return_tensors='pt', truncation=True, padding=True)
output = model(**tokens)
return output.last_hidden_state.mean(dim=1).detach().numpy()
df['embedding'] = df['text'].apply(bert_embedding)
embeddings = np.vstack(df['embedding'].values)
# 3. 데이터 스케일링
scaler = MinMaxScaler()
scaled_embeddings = scaler.fit_transform(embeddings)
# 4. LSTM 모델 생성
timesteps = 1 # 각 시간 간격으로 분석
X = np.array([scaled_embeddings[i:i+timesteps] for i in range(len(scaled_embeddings) - timesteps)])
y = scaled_embeddings[timesteps:]
model = Sequential([
LSTM(64, input_shape=(timesteps, scaled_embeddings.shape[1]), return_sequences=False),
Dropout(0.2),
Dense(scaled_embeddings.shape[1])
])
model.compile(optimizer='adam', loss='mse')
# 5. 모델 학습
model.fit(X, y, epochs=10, batch_size=1, verbose=1)
# 6. 이상치 탐지
predictions = model.predict(X)
loss = np.mean((y - predictions)**2, axis=1)
# 임계값 설정 (예: 평균 + 2표준편차)
threshold = np.mean(loss) + 2 * np.std(loss)
outliers = np.where(loss > threshold)[0]
# 이상치 출력
print(f"Detected outliers at timestamps: {df['timestamp'].iloc[outliers].values}")728x90
'DeepLearning > NLP' 카테고리의 다른 글
| [NLP] Drain3 - Python (0) | 2025.02.19 |
|---|---|
| [NLP] 텍스트 데이터 전처리 - Log Template (3) | 2025.01.13 |
| [NLP] Encoder-Decoder와 Attention (5) | 2025.01.06 |
| [NLP] 텍스트 데이터 전처리 (3) | 2025.01.05 |
| [NLP] Word Embedding (4) | 2024.11.28 |