1. 상관분석(Correlation Analysis)
: 두 변수 간의 관계의 정도를 알아보기 위한 분석방법

2. 상관분석 종류
1. 선형 상관분석(Linear Correlation Analysis)
1) 피어슨 상관계수(Pearson Correlation Coefficient)
- 두 연속형 변수 간의 선형적 관계를 측정
ex) 키와 몸무게, 온도와 습도 - 정규분포를 따르고 이상치가 없어야 함
- 값의 범위 [-1 : 1]
- 0에 가까울수록 상관관계가 약함
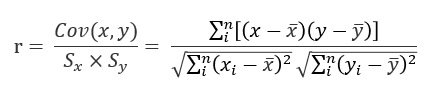
2) 부분상관 분석(Partial Correlation)
- 두 변수에서 제 3의 변수 효과를 제거한 후 상관성 분석
ex) 나이와 수면시간 분석 시 성별의 영향 제거
3) 준부분 상관분석(Semi-partial Correlation)
- 한 변수에서 제 3의 변수의 영향을 제거한 후 다른 변수와의 상관성 측정
2. 순위 상관분석(Rank Correlation Analysis)
1) 스피어만 상관계수(Spearman's Rank Correlation Coefficient)
- 비모수적 방법
- 두 변수 간 비선형적인 관계를 측정하거나 연속형 데이터가 아닌 순위 데이터(서열척도)에 사용
- 정규분포 가정 불필요
- 값의 범위 [-1 : 1]
- 값이 0에 가까울수록 순위 간의 관계가 약함
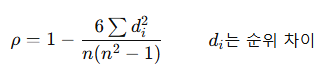
2) 켄달의 타우(Kendall's Tau)
- 두 순위형 변수 간의 상관관계를 측정
- 작은 데이터셋에 적합
- 순서 관계를 더 정교하게 특정
- 순위가 동일한 경우에도 민감하게 작동
3) Theil's U
- 비대칭적 상관분석
- 두 변수간의 순위관계를 평가
- 비선형 데이터에 적합
- 이상치에 민감할 때 사용
3. 비선형 상관분석(Nonlinear Correlation Analysis)
1) Mutual Information
- 두 변수 간의 비선형적 관계 측정
- 정보이론을 기반으로 하며, 상호 의존도를 측정
- 값이 클수록 두 변수 간의 비선형적 의존도가 높음을 의미
- 비선형 관계가 의심되는 경우 분석에 적합
2) 거리 상관관계(Distance Correlation)
- 피어슨 상관계수보다 일잔적인 경우에 사용
- 선형/비선형 관계 모두 측정 가능
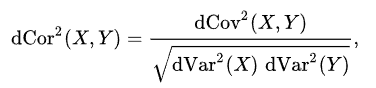
3) Hoeffding's D
- 두 변수간의 비선형 관계 탐지
- 데이터가 이상치에 민감할 떄 사용
- 정규성 가정 필요 없음
4. 이진 데이터 상관분석(Binary Correlation Analysis)
1) 파이계수(Phi Coefficient)
- 두 개의 이진 변수간의 상관성 측정
ex) 성공/실패, 맞다/틀리다, 0과 1
5. 범주형 데이터 상관분석
1) Point-Biserial Correlation
- 한 변수가 연속형, 다른 변수가 이진형일 때 사용
- 비모수적 특성
- 정규분포 가정이 필요 없음
2) Fisher's Exact Test
- 두 범주형 변수 간의 관계 평가
- 데이터 정규성을 고려하지 않음
3) Cramer's V
- 범주형 변수 간의 관계 평가
- contingency를 기반으로 계산
6. 시계열 데이터 상관분석
1) Cross-Correlation
- 두 변수 간의 시간을 고려
- 정규분포 가정이 필요 없음
2) Dynamic Time Warping Correlation
- 시계열 데이터의 비선형적 관계 평가
- 두 데이터의 패컨 유사성 측정
7. 고차원 데이터 상관분석
1) Symmetric Uncertatinty
- 정보 이론 기반으로 고차원 데이터의 변수 간 의존성 측정
- 정규성을 가정하지 않음
2) Markov Blanket
8. 기타
1) Gini Correlation
- 정규성을 따르지 않는 연속형 데이터
- 변수의 상대적 분산을 이용해 상관성 측정
- 이상치에 강함
- 정규성 가정 필요 없음
- 선형/비선형 관계 모두 측정 가능
2) Quandrant Correlation
- 단순한 데이터일 때
- 사분면 내의 점 분포를 기반으로 상관성 측정
- 이상치에 민감하지 않음
- 정규성 가정 필요 없음
- monotonic relationship 일 때에만 강점
3. 분석
Scikit-Learn에 내장되어 있는 Iris Data로 피어슨 상관분석을 하려고 한다.
분석 순서
- Iris Data Load
- 정규성 검정
- 피어슨 상관분석
정규성검정은 아래에서 참조!
정규성 검정 종류 및 Python Code
: 데이터가 정규분포를 따르는지 확인하는 통계적 방법1. 모수적 방법(Parametric Methods): 데이터가 특정 분포(정규분포 등)에 따른다고 가정하여 해당 분포의 모수(평균, 분산 등)를 추정한 후 검정:
hello-heehee.tistory.com
파이썬 코드는 다음과 같다.
from sklearn.datasets import load_iris
from scipy.stats import shapiro
from scipy.stats import pearsonr
import pandas as pd
import seaborn as sns
# Iris Data Load
iris = load_iris()
print(iris.data) # x data
print(iris.feature_names) # x column name
print(iris.target) # y data
print(iris.target_names) # y name 0: setosa, 1: versicolor, 2: virginica
df = pd.DataFrame(data=iris.data, columns=iris.feature_names) # ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
df.describe() # 열 별 통계량 요약
#정규성 검정
sns.scatterplot(data=df, x='sepal length (cm)', y='petal length (cm)') #산점도
stat_x, p_x = shapiro(df['sepal length (cm)']) #Shapiro-Wilk Test
stat_y, p_y = shapiro(df['petal length (cm)']) #Shapiro-Wilk Test
#피어슨 상관분석
r, p = pearsonr(df['sepal length (cm)'], df['petal length (cm)'])
print("correlation: {} p-value: {}".format(round(r, 3), round(p,5)))- Iris Data Load
Iris 데이터는 영국의 통계학자이자 생물학자인 Fisher가 아이리스 꽃에 대해 만든 다변량 데이터 셋으로,
세 가지 종류의 아이리스 꽃(Setosa, Virginica, Versicolor)에 대해서 꽃받침(sepal)과 꽃잎(petal)의 길이(length)와 너비(width)에 대해서 측정한 데이터다.
{Dataframe}.describe() 함수는 Dataframe에 대한 기초통계량을 요약해준다

- 정규성 검정
정규성 검정은 두가지로 진행하였으며, 첫 번째는 Q-Q Plot이다.
Q-Q Plot은 데이터 X, Y가 직선을 이루는지에 대해서 정규성을 따르는지 검토하는데, 실제 데이터들이 직선을 따르는지 판단하기가 분석가마다 개인적 견해가 다를 수 있다.

두 번째 방법은 Shapiro-Wilk 검정이다. 이 방법은 이미 데이터가 정규분포가 따른다고 가정하고 사용한다.
그랬을 때 'sepal length'와 'petal length'의 경우 p값은 각각 0.01, 0.00으로 p값이 유의수준 0.5보다 작기 때문에,
귀무가설(데이터는 정규분포를 따른다)을 기각하고 대립가설(데이터는 정규분포를 따르지 않는다.)를 채택해야한다.
실제 이 상태로 피어슨 상관분석을 하면 오분석이지만, 분석을 수행하면 검정통계량은 0.87, p값은 0.00으로 유의수준 0.5보다 작기 때문에, 귀무가설(두 변수는 상관관계가 없다)을 기각하고 대립가설(두 변수는 상관관계가 있다)을 채택한다.
따라서 두 데이터 셋은 선형적 상관관계가 있다고 해석한다.
import numpy as np
from scipy.stats import kstest, norm
#정규성 검정
stat_k, p_k = kstest(df['sepal length (cm)'], 'norm') #Kolmogorov-Smirnov Test
#상관분석
#GINI Correlation
def gini_mean_difference(x):
n = len(x)
diff_sum = 0
for i in range(n):
for j in range(n):
diff_sum += abs(x[i] - x[j])
return diff_sum / (n * n)
def gini_correlation(x, y):
if len(x) != len(y):
raise ValueError("x and y must have the same length")
gmd_x = gini_mean_difference(x)
gmd_y = gini_mean_difference(y)
gmd_xy = gini_mean_difference(x + y)
return (gmd_x + gmd_y - gmd_xy) / np.sqrt(gmd_x * gmd_y)
x = df['sepal length (cm)']
y = df['petal length (cm)']
gini_corr = gini_correlation(x, y)
print("Gini Correlation:", gini_corr)- 정규성검정: 비모수검정
데이터가 특정 분포를 따르지 않을 때 사용하는 Kolmogorov-Smirnov 검정 수행시 p값은 0.00으로 유의수준 0.5보다 작기 때문에 귀무가설(정규분포를 따른다)를 기각하고 대립가설(정규분포를 따르지 않는다)를 채택한다.
- 상관분석: Gini Correlation
Gini Correlation은 파이썬 내장 함수가 없어서 Chat-GPT 도움을 받아 함수를 완성하였다.
gini_corr의 값은 0.04로 단조적인 관계가 거의 없음을 나타낸다.
단조적 관계란 x와 y가 선형적으로 증가하되, 그 크기가 일정한 것을 의미한다.
분석결과를 종합해보면, 꽃받침 길이와 꽃잎의 길이는 선형적 관계는 있지만 단조적 관계는 없다.
'통계학 > 통계' 카테고리의 다른 글
| [통계분석] ANOVA (분산분석) (2) | 2024.12.23 |
|---|---|
| [통계분석] t-test (t-검정) (2) | 2024.12.22 |
| 정규성 검정 종류 및 Python Code (3) | 2024.12.07 |
| [확률분포] 연속형 확률분포 (2) | 2024.12.01 |
| [확률분포] 이산형 확률분포 (5) | 2024.11.30 |