728x90
1. 일표본 t-검정(one sample t-test)
: 단일 모집단에서 관심이 있는 연속형 변수의 평균 값을 특정 기준값과 비교하고자 할 때 사용하는 검정방법
- 모집단의 구성요소들이 정규분포를 이룬다는 가정하에 검정통계량 값을 계산 (정규성)
- 종속변수는 연속형 변수
- 작은 표본일 때 사용 (30개 미만)
- Outlier에 민감
1) 가설설정
- 귀무가설: μ= μ_0
- 대립가설: μ!= μ_0 (양측검정), μ> μ_0 (단측검정), μ< μ_0 (단측검정)
2) 유의수준 설정
3) 검정통계량 값 및 유의확률 계산

4) 기각여부 판단 및 의사결정
- p-value < 유의수준: 귀무가설을 기각하고 대립가설을 채택
- p-value > 유의수준: 귀무가설 채택
- t-값이 클수록 두 그룹간의 차이가 유의미 (귀무가설 기각, 대립가설 채택)
> Example
from scipy.stats import ttest_1samp
data = [2.1, 2.5, 2.8, 3.0, 3.1]
t_stat, p_value = ttest_1samp(data, popmean=2.5, alternative='two-sided')
print("t-statistic:", t_stat, "p-value:", p_value)
"""
Result:
t-statistic: 1.1009637651263593 p-value: 0.33271051350838393
"""- 귀무가설: μ=2.5, 대립가설 μ!=2.5
- 유의수준 alpha = 0.05
- 검정통계량 1.1, p-value: 0.33
- 결론: p-value가 유의수준 0.05보다 크므로 귀무가설을 기각할 수 없다. 즉, data들의 모평균은 2.5라 할 수 있다.
- 검정통계량으로 결론을 내는 방법은 아래와 같다.
t검정 표는 맨 하단에 첨부.
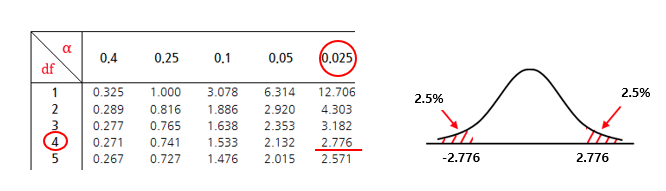
양측 검정이기 때문에 alpha 값은 0.025이고 자유도는 n-1=4이다. 이때의 값은 2.776으로, 검정통계량 t=1.1은 기각역(빨간부분)이 아닌 채택역에 있기때문에 귀무가설을 채택한다.
2. 대응표본 t-검정(paired sample t-test)
:단일 모집단에 대해 두 번의 처리를 가했을 때, 두 개의 처리에 따른 평균의 차이를 비교하고자 할 때 사용하는 검정방법
- 짝지어진 t-검정(matched pair t-test)이라고도 함
- 표본 내의 개체들에 대해서 두번의 측정 실시. 즉, 모집단과 표본은 하나씩이지만 모수는 2개
1) 가설검정
- 귀무가설: 두 개의 모평균 간에는 차이가 없다
- 대립가설: 두 개의 모평균 간에는 차이가 있다 (양측검정)
- 두 개의 모평균 간의 차이는 0보다 크다 (단측검정)
- 두 개의 모평균간의 차이는 0보다 작다 (단측검정)
2) 유의수준 설정
3) 검정통계량의 값 및 유의확률 계산

4) 기각여부 판단 및 의사결정
> Example
from scipy.stats import ttest_rel
before = [2.1, 2.5, 2.8, 3.0, 3.1]
after = [2.3, 2.7, 2.6, 3.1, 3.2]
t_stat, p_value = ttest_rel(before, after)
print("t-statistic:", t_stat, "p-value:", p_value)
"""
Result:
t-statistic: -1.0886621079036367 p-value: 0.3375018565403639
"""- 귀무가설: μ1 = μ 2, 대립가설 μ1 != μ2
- 유의수준 alpha = 0.05
- 검정통계량: -1.09, p-value: 0.34
- 결론: p-value가 유의수준 0.05보다 크므로 귀무가설을 기각할 수 없다. 즉, data들의 차이는 통계적으로 유의미하지 않다.
3. 독립표본 t-검정(independent sample t-test)
: 두 개의 독립된 모집단의 평균을 비교할 때 사용하는 검정방법
- 정규성 만족
- 두 개의 모집단은 서로 독립적
- 두 모집단의 분산이 서로 같음 (등분산성) - 등분산 검정 먼저 수행
- 독립변수는 범주형, 종속변수는 연속형
1) 가설검정
- 귀무가설: μ1= μ2
- 대립가설: μ1! = μ2 (양측검정), μ1 > μ2 (단측검정), μ1 < μ2 (단측검정)
2) 유의수준 설정
3) 등분산 검정
- 귀무가설: 두 집단의 분산이 동일하다.
- 대립가설: 두 집단의 분산이 동일하지 않다.
Levene's Test, Barlett's Test 로 확인.
4) 검정통계량의 값 및 유의확률 계산
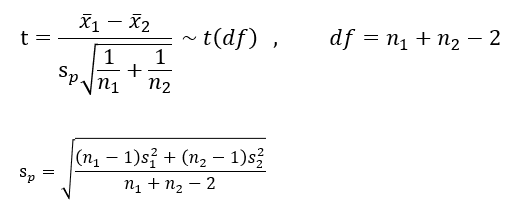
5) 기각여부 판단 및 의사결정
> Example
from scipy.stats import ttest_ind
group1 = [2.1, 2.5, 2.8, 3.0, 3.1]
group2 = [2.3, 2.6, 2.7, 2.9, 3.0]
t_stat, p_value = ttest_ind(group1, group2, equal_var=True) # equal_var=False for Welch's T-test
print("t-statistic:", t_stat, "p-value:", p_value)
"""
Result:
t-statistic: -2.026980648162706e-15 p-value: 0.9999999999999984
"""- 귀무가설: μ1 = μ 2, 대립가설 μ1 != μ2
- 유의수준 alpha = 0.05
- 검정통계량: -2.03, p-value: 0.99
- 결론: p-value가 유의수준 0.05보다 크므로 귀무가설을 기각할 수 없다. 즉, 두 집단의 모평균은 동일하다.
4. t 검정표
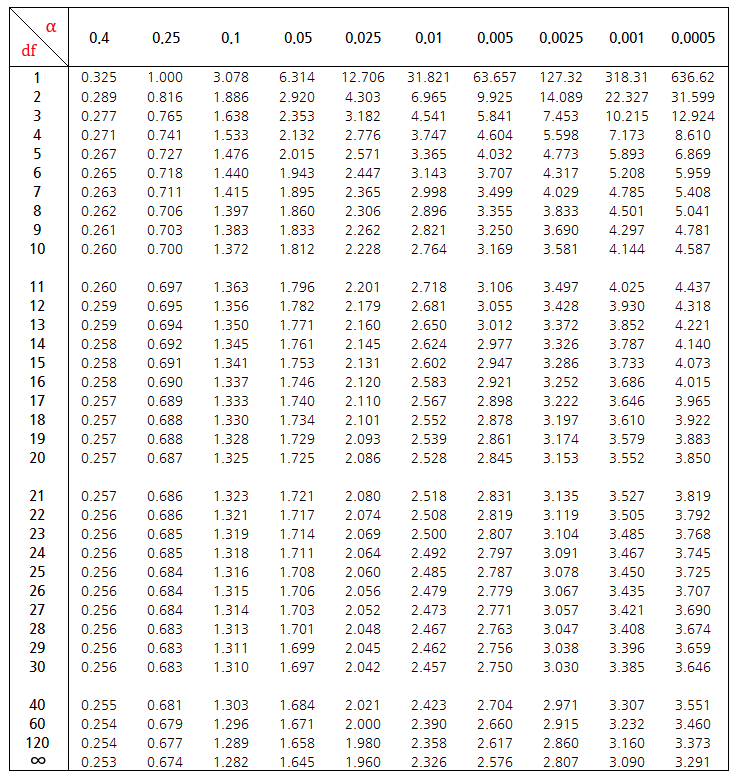
728x90
'통계학 > 통계' 카테고리의 다른 글
| [통계분석] 시계열 분석 (5) | 2025.01.04 |
|---|---|
| [통계분석] ANOVA (분산분석) (2) | 2024.12.23 |
| 상관분석 정의 및 종류 + 예시(w. Python) (4) | 2024.12.09 |
| 정규성 검정 종류 및 Python Code (3) | 2024.12.07 |
| [확률분포] 연속형 확률분포 (2) | 2024.12.01 |